前段时间学习 3fs,提到它在使用 CRAQ (Chain Replication with Apportioned Queries)作为复制的算法,恰巧工作中有类似的需求,在这里记录一下对 CRAQ 的理解。
在某种意义上讲,CRAQ 已经是对象存储或者 KV 在做复制时相当流行的工程方案,而 CRAQ 可以看作是对传统的链式复制的一个简单的增强。不过与 Raft 这类共识算法不同,CRAQ 只关注数据复制本身,它仍然需要显式依赖一个外部的强一致配置中心(如 etcd 或 ZooKeeper)来管理复制链的拓扑信息。
链式复制
链式复制相比 Master/Slave 或 Quorum 方案,最大的不同就在于副本的写入流量不是从一个节点 fan-out 到多个节点,而是像流水线一样,从固定的 Head 节点开始,每个节点把数据传给下一个节点,直到抵达 Tail 节点。
这样的好处就是把写流量均摊给多个节点的多张网卡,更容易跑高整体的带宽。
传统的链式复制的机制下,写入到 Tail 节点就将数据视为 Committed,所有读取请求也都由 Tail 节点响应,以保证读取到最新数据。
这个机制非常简单,但问题也非常明显:读流量单点在 Tail 节点上,没办法跟随副本数的个数来扩展读的能力。
CRAQ
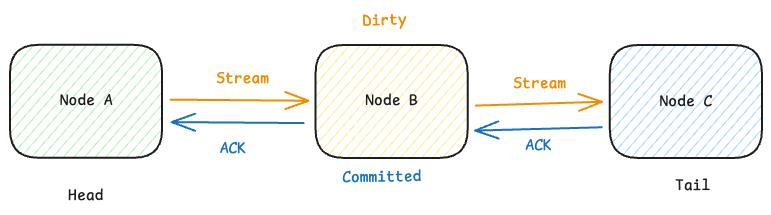
CRAQ 针对传统链式复制的增强,就在于这个读能力的扩展方面。它允许每个节点都能响应读请求。
写入流程
在写入链路上,每个节点在接受写入时,通过 Head 节点为该对象分配一个新的、单向递增的版本号,并将该版本标记为 Dirty。
当写入抵达 Tail 节点时,该版本的写入会视为 Committed,随后 Tail 节点会向前驱节点返回一个 ACK。前驱节点收到 ACK 后,会在本地也将这个版本标记为 Committed,并继续向前驱节点转发 ACK,直到 ACK 最终抵达 Head 节点。在收到 ACK 之后,该节点便可以安全地回收旧版本的数据了。
读取流程
在任意节点收到读取请求时,会检查一下这个对象的最新版本是不是 Committed 状态:
- 如果是,就直接返回该版本的数据;
- 如果不是(Dirty 状态),则询问一下 Tail 节点最新的 Committed 的版本是多少,返回本地的对应版本;
可见 CRAQ 在以下两种场景中,都能较好地实现读取请求的负载均衡:
- 对于常规的读多写少的场景,多数对象都已完成了 Commit,也就意味着任意节点在大概率上都可以直接响应读请求;
- 对于频繁变动的对象写入,对于有 Dirty 数据的对象,只需增加一次向 Tail 节点查询版本元信息的开销,由于当前节点本地同时持有新旧版本的数据,一旦确认版本号,数据可直接从本地返回,无需从 Tail 节点传输数据;
并发写入
CRAQ 在这里还有一个妙处,就是绕开了并发写冲突的问题。
如果两个客户端同时向 Head 节点写入同一个对象,链式复制天然保证了顺序:先到达 Head 节点的请求就先被处理,后到的会被排队。Head 节点对针对特定的一个对象,总是按串行化的顺序来处理请求。这就将分布式环境下的并发写冲突,转化为了 Head 节点上的本地串行化处理,自然也就不存在 Quorum 机制中的 Write-Write Conflict 问题。
配置管理
CRAQ 假设依赖外部配置中心管理拓扑,但算法本身仍需处理节点变更与故障恢复。以下讨论均基于一个外部强一致配置中心(如 etcd)的存在。
节点的摘除
假设有一个复制链条 [N1, N2, N3, N4],其中 N1 为 Head 节点,N4 为 Tail 节点。
- 如果 Head 节点
N1失联,则N2可被提升为新 Head。 - 如果是中间节点失联,则将其从链中摘除,让其前后节点直连即可。
- 如果 Tail 节点
N4失联,则N3可被提升为新 Tail。
Tail 节点的修复会特殊一点。更之前的节点失联,都可以当作写入失败什么都没有发生过即可。不过数据一旦落到 Tail 节点,就被认为是 Committed 了,不可以丢失。在 Tail 节点失联时,我们需要将 Tail 节点上已 Committed 的数据都恢复出来。这里幸运的是,这些数据在 Tail 的前驱节点上都保存着,只要将 Tail 的前驱节点上 Dirty 的数据统统 Commit 掉,就一定可以恢复出来 Tail 节点上 Committed 的数据。
拓扑信息的本地缓存
上面的节点拓扑的改动都体现在共识的配置中心中,所有节点一致就可以。
不过有个问题,我们依赖 etcd 这种共识服务是不假,但是如果每个读写请求都要过一次共识也未免昂贵一些。
比较实际的做法似乎还是每个节点都订阅配置中心的最新内容,在本地记录一份缓存,并记录一个拓扑版本号。每个写入、读取请求,在涉及传播多个节点时,都向其他节点传递上当前节点的拓扑版本号。对端的节点在收到来自其他节点的请求时,也都判断一下版本号是否一致,若不一致,可以直接拒绝请求,引导客户端重试。
对第一个接受请求的节点而言,它在处理请求时所依据的本地拓扑快照是原子的。这相当于一种请求级的乐观锁机制:请求携带拓扑版本号在节点间传播,对端校验版本是否匹配,不匹配则拒绝。整个过程无需与 etcd 这种共识服务进行实时的协调开销。
链条的重配置
如果集群的控制面发现节点有掉线,那么可以发起链条的重新配置。
重新配置时,可以摘掉失败的节点,组成新的拓扑,让链条中的所有节点的数据完全一致之后,再让它们恢复对外服务。
重配置时,配置中心(通过 etcd 等共识服务)确定新拓扑并下发。各节点根据自己在新拓扑中的位置和本地状态,按照确定性规则完成数据修复:
- 新 Tail 节点将本地所有 Dirty 数据提升为 Committed,并向前驱节点发送 ACK;
- 其他节点根据收到的 ACK 更新本地状态;
整个数据修复过程是确定性的,由各节点独立执行,无需引入额外的共识机制来协调数据状态。共识仅用于拓扑变更本身。
新增节点
假设现有复制链条 [N1, N2, N3],现在要新增一个节点 N4 作为新的 Tail 节点。大致上是:
- 先在后台使 N4 追上 T 时刻的 N3 的数据;
- 找 Head 节点设置链条为 “Locked” 状态暂停写入,并更新配置中心的新链条拓扑为
[N1, N2, N3, N4]; - 确保
N4完全同步N3的数据(包括所有 Dirty 和 Committed 版本); - 使
N4作为新 Tail,将本地所有 Dirty 数据提升为 Committed,并向前驱节点N3发送 ACK,触发整条链完成提交。待所有节点数据一致后,将链状态修改为 Ready,恢复对外服务;
这里第二步标记链条为 “Locked” 状态,同样可以不依赖共识服务的实时读写,而直接找 Head 节点就够了。这里可以把链条的状态看作一个内置的元信息,按常规的复制逻辑进行设置即可。
这里虽然是暂停写,但对用户不一定有感,SDK 可在收到写入暂停时进行透明重试。想必应该也有更平滑的流程,这里先掠过。
总结
感觉 CRAQ 在设计上整体上还是非常巧妙的一套设计:让写入收敛到 Head 节点对请求做串行化处理,读取时将 Tail 节点作为最新版本的 Oracle,在一致性方面无形中简化了许多细节。而流式的复制也能把多机的网卡利用起来,把带宽均摊起来,也非常巧妙的用暴力去缓解了 “强一致性” vs “性能” 的 Trade Off。
另一方面,将高可用完全交给了控制面,与数据面几乎解耦了,因此需要一个集群管理在控制面对节点做积极的健康检查,并在必要时调整拓扑的布局。好处是数据面仍只需要关注数据的复制与确认,关注点更专一,不过也需要控制面做更多的工作来维护整个系统的可用性,按说是工程中需要主要放精力的地方。