prometheus 是时下最流行的监控组件,能够从各种目标抓取指标落到时序数据库里,并提供很灵活的聚合查询能力。本文尝试整理一下 prometheus 的存储与索引的结构,了解它如何做到复杂的聚合查询支持的。
时序数据的存储
在 prometheus 的 ppt 中提到 tsdb 存储设计有这几个难点:
- 指标数据有 “Writes are vertical,reads are horizontal” 的模式;
- high churn:云原生环境下会产生大量的临时性的时间序列;
“Writes are vertical,reads are horizontal” 的意思是 tsdb 通常按固定的时间间隔收集指标并写入,会 “垂直” 地写入最近所有时间序列的数据,而读取操作往往面向一定时间范围的一个或多个时间序列,“横向” 地跨越时间进行查询:
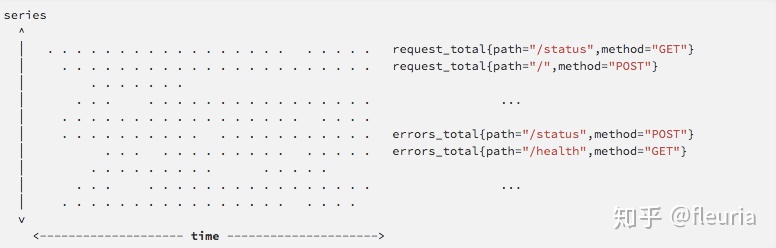
鉴于此,prometheus 写入的方法与 LSM Tree 类似,会通过一个缓冲攒够批次再落盘,使单个时间序列的一段 chunk 在存储上相邻,从而允许能够较为快速地横向读取到时间序列数据。prometheus tsdb 会像 Gorilla 那样,对一个 chunk 做压缩,使单个监控数据点的存储成本小到 1.4 bytes 这个水平。这点跟列存的设计比较相似,压缩不只是对存储成本的优化,也对计算的加速能够起到很大作用。
“high churn” 现象导致 graphite 那种每个时间序列一个文件的做法变得不那么容易续了,每个 pod 一生一死就一个时间序列,一来一回就多一个文件,很容易撑爆 inode,此外跟随查询频繁打开、关闭文件也不那么经济。 prometheus v1 的存储架构仍是一个文件对应一个时间序列的存储设计,到 v2 架构中做了一项大重构,改为每两小时落一个 Block,使这个 block 包含最近两小时的所有时序数据与索引,通过 mmap 访问 block 数据。每个 block 实质上相当于一个独立的小数据库,存储着这两小时内的所有时间序列的 chunk 数据与索引。
v2 的目录结构大约长这样:
$ tree ./data
./data
├── b-000001
│ ├── chunks
│ │ ├── 000001
│ │ ├── 000002
│ │ └── 000003
│ ├── index
│ └── meta.json
├── b-000004
│ ├── chunks
│ │ └── 000001
│ ├── index
│ └── meta.json
├── b-000005
│ ├── chunks
│ │ └── 000001
│ ├── index
│ └── meta.json
└── b-000006
├── meta.json
└── wal
├── 000001
├── 000002
└── 000003
每个 block 中时序数据的存储大致上长这样:
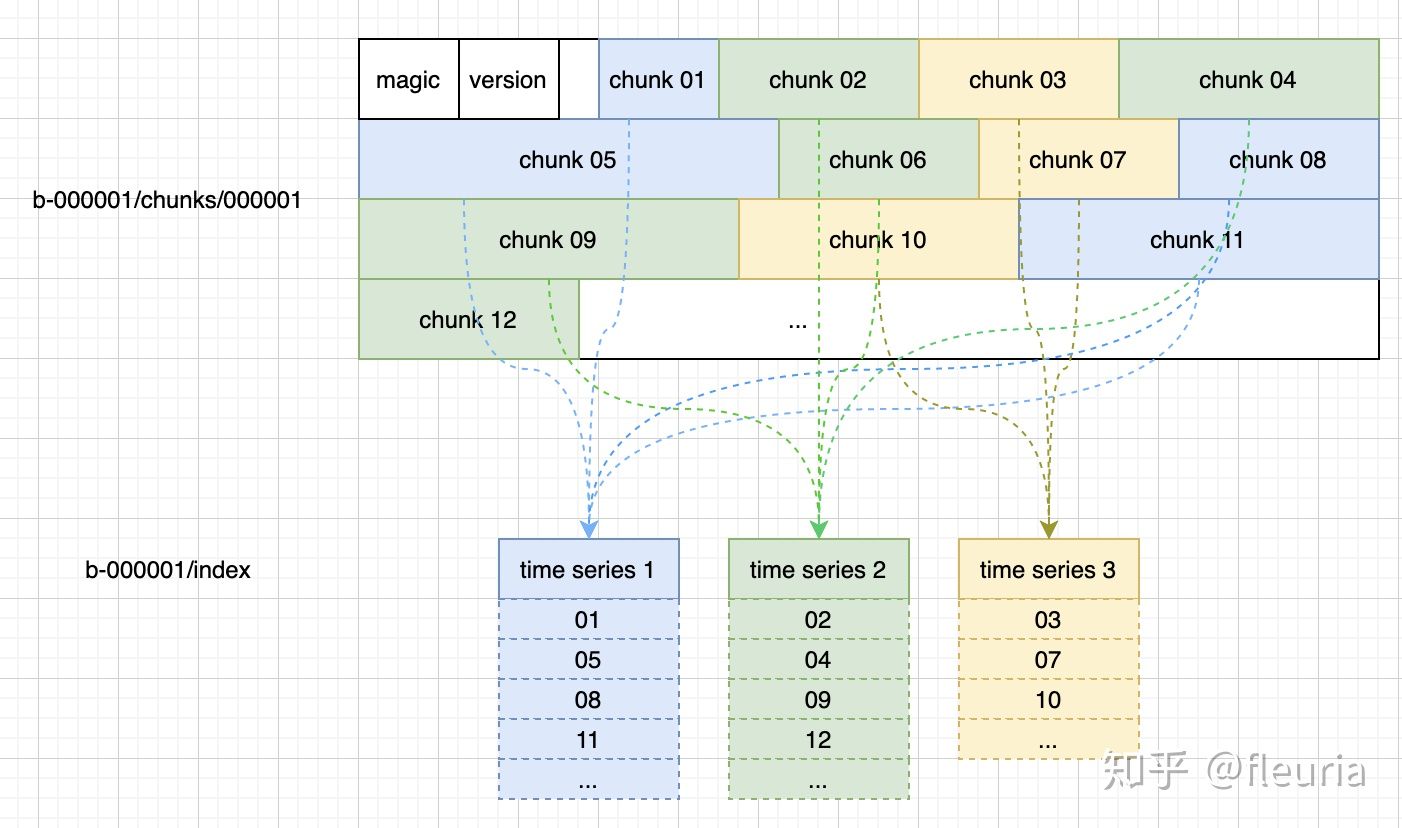
每个 chunk 可以理解为 kv 存储中的一条 kv 数据,按索引中 chunk id 的列表,形成完整的时间序列数据。
索引结构
每个 block 中的 index 文件包含这几个部分:
- symbol table:数据字典,使每个 label 的名字和 label 值,都在 symbol table 中记录为唯一 id,存储时只保存 id 值就可以了。
- series 列表:记录当前 block 中有哪些 series,每个 series 有哪些 label 值,有哪些 chunks,每个 chunk 的开始、结束时间;
- 倒排索引(posting):每个 label 值到 series id 列表的倒排;
- 倒排索引的 offset table:每个倒排列表的起始 offset;
- toc:index 文件中各部分的起始 offset;
至于 prometheus 能够根据 label 做灵活的过滤、聚合等操作,这就都属于倒排索引的功劳了,每个倒排索引都是有序的 id 排列,这样能够很高效的做到交集、并集操作:

总结
- prometheus 的存储理念受 Gorilla 影响最大,对时序数据做压缩,既节省存储又加速计算;
- v2 存储使用两小时一个 block 的结构存储时间段内所有的时序数据,时序数据进一步分为 chunk,按索引将 chunks 串为完整的时序数据;
- label 的索引是一个倒排索引的结构,这些倒排索引是灵活的聚合查询的基础;