Recently while studying 3fs, I learned that it uses CRAQ (Chain Replication with Apportioned Queries) as its replication algorithm. Coincidentally, I had similar requirements at work, so I’m documenting my understanding of CRAQ here.
CRAQ is already a quite popular engineering solution for replication in object storage or KV systems. CRAQ can be viewed as a simple enhancement to traditional chain replication. However, unlike consensus algorithms like Raft, CRAQ only focuses on data replication itself. It still requires explicit dependency on an external strongly consistent configuration center (such as etcd or ZooKeeper) to manage the topology information of the replication chain.
Chain Replication
The biggest difference between chain replication and Master/Slave or Quorum schemes is that the write traffic to replicas doesn’t fan-out from one node to multiple nodes. Instead, it flows like a pipeline: starting from a fixed Head node, each node passes data to the next node until it reaches the Tail node.
The benefit of this approach is that write traffic is distributed across multiple network interfaces on multiple nodes, making it easier to achieve higher overall bandwidth.
Under traditional chain replication mechanisms, data is considered Committed once it reaches the Tail node, and all read requests are served by the Tail node to ensure reading the latest data.
This mechanism is very simple, but the problem is also obvious: read traffic becomes a single point at the Tail node, making it impossible to scale read capacity with the number of replicas.
CRAQ
CRAQ’s enhancement to traditional chain replication lies in scaling read capacity. It allows every node to serve read requests.
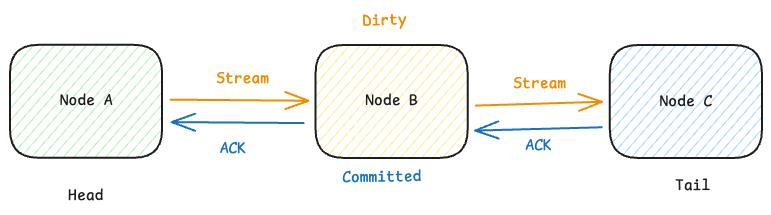
Write Flow
In the write path, when each node accepts a write, the Head node assigns a new, monotonically increasing version number for that object and marks that version as Dirty.
When the write reaches the Tail node, that version’s write is considered Committed. The Tail node then returns an ACK to its predecessor node. After receiving the ACK, the predecessor node marks the version as Committed locally and continues forwarding the ACK to its predecessor until the ACK eventually reaches the Head node. After receiving the ACK, the node can safely reclaim old version data.
Read Flow
When any node receives a read request, it checks whether the latest version of that object is in Committed state:
- If yes, it directly returns that version’s data;
- If not (Dirty state), it queries the Tail node for the latest Committed version and returns the corresponding local version;
It’s clear that CRAQ can achieve good load balancing for read requests in the following two scenarios:
- For typical read-heavy workloads, most objects have completed Commit, meaning any node can likely serve read requests directly;
- For frequently changing object writes, for objects with Dirty data, there’s only one additional query to the Tail node for version metadata. Since the current node holds both new and old version data locally, once the version number is confirmed, data can be returned directly from local storage without transferring data from the Tail node;
Concurrent Writes
CRAQ has another clever aspect here - it bypasses concurrent write conflict issues.
If two clients simultaneously write to the same object at the Head node, chain replication naturally guarantees ordering: the request that arrives at the Head node first is processed first, and later ones are queued. The Head node always processes requests for a specific object in serialized order. This transforms concurrent write conflicts in distributed environments into local serialized processing at the Head node, naturally avoiding the Write-Write Conflict problem in Quorum mechanisms.
Configuration Management
CRAQ assumes dependency on an external configuration center to manage topology, but the algorithm itself still needs to handle node changes and failure recovery. The following discussions all assume the existence of an external strongly consistent configuration center (like etcd).
Node Removal
Assume there’s a replication chain [N1, N2, N3, N4], where N1 is the Head node and N4 is the Tail node.
- If Head node
N1becomes unreachable,N2can be promoted to become the new Head. - If a middle node becomes unreachable, it’s removed from the chain, and its predecessor and successor nodes connect directly.
- If Tail node
N4becomes unreachable,N3can be promoted to become the new Tail. In this case,N3must promote all locally marked Dirty data to Committed status and send ACK to predecessor nodes to ensure no data loss.
Tail node repair is a bit special. When previous nodes become unreachable, it can be treated as if the write failed and nothing happened. However, once data reaches the Tail node, it’s considered Committed and cannot be lost. When the Tail node becomes unreachable, we need to recover the Committed data from the Tail node. Fortunately, this data is preserved on the Tail’s predecessor nodes. By committing all Dirty data on the Tail’s predecessor node, we can definitely recover the Committed data from the Tail node.
Local Cache of Chain Topology
The topology changes mentioned above are all reflected in the consensus-based configuration center, and all nodes remain consistent.
However, there’s an issue. While we do rely on consensus services like etcd, it would be expensive to go through consensus for every read/write request.
A more practical approach seems to be having each node subscribe to the latest content from the configuration center, maintain a local cache, and record a topology version number.
For each write or read request involving propagation across multiple nodes, the current node passes along its topology version number. When a peer node receives a request from another node, it checks whether the version numbers match. If they don’t match, it can directly reject the request and guide the client to retry.
For the first node receiving the request, the local topology snapshot it uses during processing is atomic. This is essentially a request-level optimistic locking mechanism: requests carry topology version numbers during inter-node propagation, peers verify version match, and reject if mismatched. The entire process doesn’t require real-time coordination overhead with consensus services like etcd.
Chain Reconfiguration
If the cluster’s control plane detects a node is offline, it can initiate chain reconfiguration.
During reconfiguration, failed nodes can be removed to form a new topology. After ensuring all nodes in the chain have completely consistent data, they can resume serving externally.
During reconfiguration, the configuration center (through consensus services like etcd) determines and distributes the new topology. Each node completes data repair according to deterministic rules based on its position in the new topology and local state:
- The new Tail node promotes all local Dirty data to Committed and sends ACK to predecessor nodes;
- Removed nodes are directly removed from topology, and their uncommitted data is considered lost;
- Other nodes update local state based on received ACKs;
The entire data repair process is deterministic and executed independently by each node without introducing additional consensus mechanisms to coordinate data state. Consensus is only used for topology changes themselves.
Adding New Nodes
Assume an existing replication chain [N1, N2, N3], and now we want to add a new node N4 as the new Tail node. The process is roughly:
- First, have N4 catch up to N3’s data at time T in the background;
- Ask the Head node to set the chain to “Locked” status to pause writes, and update the configuration center with the new chain topology
[N1, N2, N3, N4]; - Ensure
N4fully synchronizesN3’s data (including all Dirty and Committed versions); - Make
N4the new Tail, promote all local Dirty data to Committed, and send ACK to predecessor nodeN3, triggering the entire chain to complete commits. After all nodes have consistent data, change the chain status to Ready and resume serving externally;
The second step of marking the chain as “Locked” status also doesn’t require real-time reads/writes from consensus services, but can directly go to the Head node. The chain state can be viewed as built-in metadata that is set using normal replication logic.
Although this involves pausing writes, users may not notice it. The SDK can transparently retry when receiving a write pause. There may be smoother processes, but I’ll skip that for now.
Summary
- CRAQ, as a chain replication mechanism, can utilize multi-machine bandwidth during both writes and reads;
- During writes, CRAQ always goes to the Head node, which serializes writes and avoids the Write-Write Conflict problem that Quorum needs to solve;
- During reads, the Tail node acts as the latest version oracle, while predecessor nodes always have the data itself, so data transfer traffic can also be distributed;
- CRAQ relies on an external configuration center to store topology metadata, and can ensure metadata version consistency across different nodes through version numbers in requests;
- CRAQ’s failure recovery logic is tightly coupled with topology change consensus, but consensus only relates to topology changes; data recovery processes are almost decoupled from consensus;