Notes on Duckdb: Build Pipelines
25 Feb 2023 by fleuria
最近两年一直比较想学习下 duckdb,断断续续看了一点不大详细,这里先记录一下它的 Pipeline 模型的概念和初始化部分。
从 Pull 模型到 Push 模型
duckdb 现在是一套标准的 Push based execution,与之相对,它在过去曾是 Pull based execution。为什么要换呢?
在这个 issue https://github.com/duckdb/duckdb/issues/1583 中有作者介绍相关的心路历程。
在过去 Pull based execution 时代,开发一个算子比较类似 volcano 那种一次迭代一个 Chunk 的模型。每个算子提供一个 GetChunk 方法,然后它也通过 GetChunk 去得到上一个算子吐回来的 Chunk,做处理后返回。
Pull 模式在早期 PoC 阶段,会更容易上手产出一套可用的系统。算子是一棵树,Pull 模型下执行整个 Query 就是拉这颗树的树根从而驱动整个执行过程,很函数式。不过 Pull 模式也有几个明显的缺点,导致它与 Pipeline 并行不那么合拍。个人感觉最主要的因素还是调度的可控性方面,Query 执行的控制流掌握在算子手中,调度器想要拆开这棵树做并行就相对无从下手,想并行就得在算子内部写并行逻辑,就更破坏封装了。
反观 Push-based 模型下,每个算子不会直接调用下游的迭代器来获取数据,而是在回调函数中接收上游的数据。个人把这点理解成一种控制反转,每个算子放弃对控制流的管控,换取调度器可以做更多的事情,由调度器从上游的算子中得到数据后喂给下游的算子,由调度器来管理数据的流向并驱动整个执行过程。
更重要的是,算子树会转换成为诸多 Pipeline 构成的物理计划,将 Pipeline 作为调度的单位,每个 Pipeline 内部更是可以并行执行,从而将并行的潜力完全的释放出来。
Pipeline Breaker
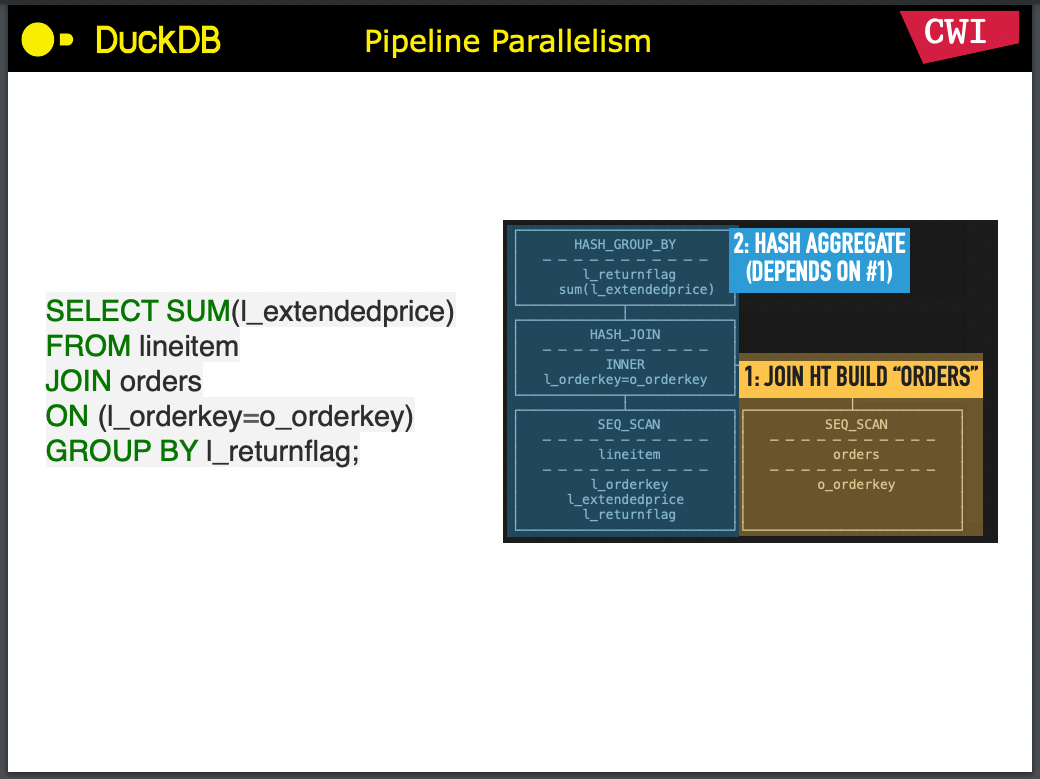
Pipeline 存在有依赖关系,在上面图里的 2 号流水线,就会在 1 号流水线跑完之后才能开始跑。其中 1 号流水线最末尾的算子 JOIN HT BUILD “ORDERS” 称作 “Pipeline breaker”。
Pipeline breaker 意味着这个 Pipeline 必须完成对所有源数据的消费之后才能返回结果。以上图中的 Query 为例,Hash Join 中没有跑完右侧的 Build 之前,跑左侧的 Probe 是没有意义的。可见这往往会是一项比较重的操作。至于 Pipeline Breaker 的存在,就是 Pipeline 在物理计划中划分的依据。
如果 Query 中间没有 Pipeline Breaker,比如 SELECT * FROM orders WHERE id > 10,就可以一条流水线走到底,不需要做依赖调度。
所以 Push 模型下,调度器需要做的第一件事情,就是排列好 Pipeline 之间的依赖关系,使前置的 Pipeline 先执行完毕,再执行依赖它的 Pipeline。
Sink
在 duckdb 中 Pipeline Breaker 就是 Sink 算子,它会安排在每个流水线的末尾,Sink 在消费完所有上游的数据后,往往也可以作为下游 Pipeline 的 Source 去产出数据。
Sink 主要有这三个接口:
//! The sink method is called constantly with new input, as long as new input is available. Note that this method
//! CAN be called in parallel, proper locking is needed when accessing data inside the GlobalSinkState.
virtual SinkResultType Sink(ExecutionContext &context, GlobalSinkState &gstate, LocalSinkState &lstate,
DataChunk &input) const;
// The combine is called when a single thread has completed execution of its part of the pipeline, it is the final
// time that a specific LocalSinkState is accessible. This method can be called in parallel while other Sink() or
// Combine() calls are active on the same GlobalSinkState.
virtual void Combine(ExecutionContext &context, GlobalSinkState &gstate, LocalSinkState &lstate) const;
//! The finalize is called when ALL threads are finished execution. It is called only once per pipeline, and is
//! entirely single threaded.
//! If Finalize returns SinkResultType::FINISHED, the sink is marked as finished
virtual SinkFinalizeType Finalize(Pipeline &pipeline, Event &event, ClientContext &context,
GlobalSinkState &gstate) const;
和 MapReduce 里的 Shuffle 有点像。每个线程有一个 LocalSinkState,在消费完数据后,本地线程 Combine 一次,最后再跑最重的 Finalize 过程将多个 LocalSinkState 的中间结果合并。比如做 Hash Aggregation,就相当于每个线程可以弄一个自己的小哈希表,这样在 Finalize 之前没有内存共享。
Pipeline 内部并行
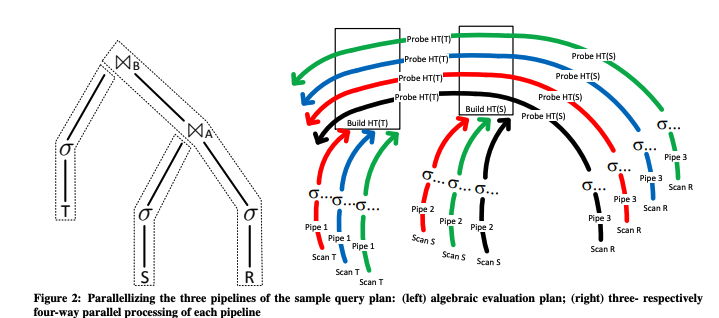
调度器需要做的另一层事情就是 Pipeline 内部的并行。像 morsel 论文中的这个图里,流水线里每条单独颜色的线就是一个线程,每条线里的算子完全一模一样。
duckdb 中每个 Pipeline 均有一个 Source 和 Sink,加上中间的 N 多无状态算子组成,其中 Source 和中间的算子可以无脑并行。比如 Scan 本地文件的 Source,可以开 M 个线程,每个线程扫描一部分文件,每次得到一个 Chunk,就可以在当前线程下喂给下一个算子,算子处理后再交给下一个算子,直到 Sink 为止。
在 duckdb Pipeline 中的一条线内部是没有再做并行的,个人猜这样反而有好处,就是内存局部性好,也没有通信开销,天然的 NUMA-aware。上游算子的一个 Chunk,可以 zero-copy 地直接 move 给下游算子,比如 Filter 算子就可以在 Chunk 原地做过滤,不再需要做内存分配,也省了一大开销。
Pipeline 的构造
有了 Pipeline 的组织形式之后,调度的粒度从 Operator 级变粗到 Pipeline 级,Pipeline 内部也更易于组织并行执行。那么 Pipeline 是怎样构造的?
先有 PhysicalOperator 树,后有 Pipeline,可以将 Pipeline 的构造理解为物理计划之后的执行计划生成。
duckdb 中的 Pipeline 最终来自每个算子的 BuildPipelines() 方法。它的函数签名如下:
virtual void BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline);
每个算子会将自己加入到当前上下文的 Pipeline ¤t 中。另一个参数 MetaPipeline 相对不那么直观,个人感觉将它改名为 PipelineBuilder 可能更容易理解一点。
MetaPipeline 只在构造 Pipeline 期间工作,帮助梳理 Pipeline 之间和内部算子的依赖关系,到运行时就只需要 Pipeline 对象了。
MetaPipeline 对象名下有一个 pipelines 数组,看 MetaPipeline 的注释,它用于维护拥有同一个 Sink 的多个 Pipeline,大部分情况下 MetaPipeline 中的 pipelines 长度还是为 1 的,主要在 UNION 语句中 pipelines 数组的长度才不为 1,这里先掠过。
MetaPipeline 的 Build() 是构造 Pipeline 的入口,不过逻辑基本等于透传给算子的 BuildPipelines 方法:
void MetaPipeline::Build(PhysicalOperator *op) {
D_ASSERT(pipelines.size() == 1);
D_ASSERT(children.empty());
D_ASSERT(final_pipelines.empty());
op->BuildPipelines(*pipelines.back(), *this);
}
大部分算子的 BuildPipelines 函数都是继承自默认行为:
void PhysicalOperator::BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline) {
op_state.reset();
auto &state = meta_pipeline.GetState();
if (IsSink()) {
// operator is a sink, build a pipeline
sink_state.reset();
D_ASSERT(children.size() == 1);
// single operator: the operator becomes the data source of the current pipeline
state.SetPipelineSource(current, this);
// we create a new pipeline starting from the child
auto child_meta_pipeline = meta_pipeline.CreateChildMetaPipeline(current, this);
child_meta_pipeline->Build(children[0].get());
} else {
// operator is not a sink! recurse in children
if (children.empty()) {
// source
state.SetPipelineSource(current, this);
} else {
if (children.size() != 1) {
throw InternalException("Operator not supported in BuildPipelines");
}
state.AddPipelineOperator(current, this);
children[0]->BuildPipelines(current, meta_pipeline);
}
}
}
在这段逻辑中,首先 meta_pipeline 中可以通过 GetState() 得到 PipelineBuildState。可以通过 state 对象来设置 Pipeline 的 Sink、Source 或追加中间 Operator。
然后是三个分支逻辑:
- 如果当前算子是 IsSink(),则将自身作为当前 Pipeline 的 Source,并通过 CreateChildMetaPipeline 创建一个新的 MetaPipeline 并递归执行 Build(),将这里作为 Pipeline Breaker 开启新的 Pipeline;
- 如果当前算子是 Source,则直接将自身作为当前 Pipeline 的 Source;
- 如果当前算子是中间的无状态 Operator,则通过 state.AddPipelineOperator 将自身追加到 Pipeline 末尾,最后按下一个算子递归执行 BuildPipelines。
总结
duckdb 的 Pipeline 抽象还是非常清晰的,下一篇笔记再单独看一下它的执行过程。